Il dato è inequivocabile: Wikipedia sta perdendo lettori. E non pochi. Secondo la stessa Wikimedia Foundation, l’ente che gestisce l’enciclopedia libera, il traffico proveniente da utenti reali è calato in modo sensibile negli ultimi mesi. E il “colpevole” è chiaro.
Anche Wikipedia perde lettori (umani): l’IA “ruba” il traffico
Tra marzo e agosto 2025, un’anomalia nei dati provenienti dal Brasile ha svelato un grande numero di accessi “umani” che in realtà erano bot in grado di aggirare i sistemi di rilevamento. Una volta corretti i conteggi, la realtà è apparsa in tutta la sua chiarezza: rispetto al 2024, Wikipedia ha perso circa l’8% di visite autentiche.
Sul lungo periodo la flessione è ancora più netta: dal marzo 2022 al marzo 2025 i referral organici (cioè le visite da motori di ricerca) sono passati da 4,61 miliardi a 3,53 miliardi al mese, secondo i dati di DataReportal. Un miliardo di click in meno.
Il motivo? Le risposte dell’intelligenza artificiale
La causa, spiega Wikimedia in un’analisi firmata da Marshall Miller, è la diffusione dei sistemi di ricerca “generativa”: le sintesi automatiche create dall’intelligenza artificiale e integrate in motori di ricerca, social e chatbot.
In pratica, sempre più utenti ottengono subito la risposta che cercano – spesso scritta dall’IA – senza bisogno di cliccare sulla fonte originale. Wikipedia, che per vent’anni è stata la porta d’ingresso del sapere online, oggi viene “saltata” perché l’informazione è già sintetizzata a monte.
Una beffa ulteriore è che Wikipedia stessa è una delle principali fonti di addestramento dei grandi modelli linguistici (LLM), come quelli usati da ChatGPT o Gemini: i sistemi si nutrono dei suoi contenuti per imparare, ma poi sottraggono a quella stessa enciclopedia traffico e visibilità.
Wikimedia aveva tentato, mesi fa, di introdurre riassunti generati da AI direttamente sulle proprie pagine, ma la sperimentazione era durata poco: la comunità di redattori aveva protestato duramente, temendo imprecisioni e perdita di trasparenza.
Per reagire alla crisi, la fondazione ha annunciato due nuovi team – “Reader Growth” e “Reader Experience” – incaricati di migliorare l’esperienza di lettura e spingere gli utenti a consultare le pagine originali. È allo studio anche un sistema di attribuzione che obblighi le piattaforme di intelligenza artificiale a riconoscere (e citare) le fonti da cui estraggono i dati.
Il messaggio è chiaro: se non si trova un equilibrio tra innovazione tecnologica e tutela delle fonti, il sapere condiviso rischia di perdere la propria trasparenza – e i propri lettori.
La tempesta sull’informazione: l’Europa contro Google e le sue “risposte automatiche”
Il caso Wikipedia non è isolato. Lo stesso meccanismo – l’intelligenza artificiale che filtra e riscrive i contenuti al posto dell’utente – sta scuotendo anche l’intero sistema dell’informazione.
Nel mirino c’è AI Overview, la nuova funzione di Google che fornisce risposte automatiche direttamente nella pagina dei risultati di ricerca. Invece di mostrare una lista di link, Google offre subito un riassunto del tema cercato, spesso tratto da articoli giornalistici, senza che l’utente debba cliccare sulle fonti originali.
La Federazione Italiana Editori Giornali (FIEG) ha presentato un reclamo formale all’Agcom contro questa funzione, accusando Google di violare alcune disposizioni del Digital Services Act (DSA) europeo. L’iniziativa, sostenuta anche dall’ENPA (European Newspaper Publishers’ Association), chiede alla Commissione europea di aprire un’istruttoria su possibili “effetti pregiudizievoli sugli utenti, sui consumatori e sulle imprese editoriali”.
“Traffic killer”: gli editori perdono fino al 25% dei lettori
Secondo gli editori, Overview sta letteralmente “mangiando” il traffico verso i loro siti. Le analisi mostrano un calo medio del 10-15% delle visite organiche, con punte fino al 25% per alcune testate.
Il fenomeno è stato ribattezzato “traffic killer”: se l’IA offre già il riassunto della notizia, pochi cliccano sul link sottostante. Il risultato è devastante per chi vive di pubblicità e abbonamenti.
A lanciare l’allarme non sono solo i quotidiani europei. Anche la storica rivista Rolling Stone ha denunciato il problema. Un esempio emblematico: cercando “festa nuovo album Sfera Ebbasta e Shiva” su Google, la prima cosa che appare è un box AI Overview che spiega in quattro righe cosa è successo. Sotto, il link all’articolo originale di Rolling Stone Italia.
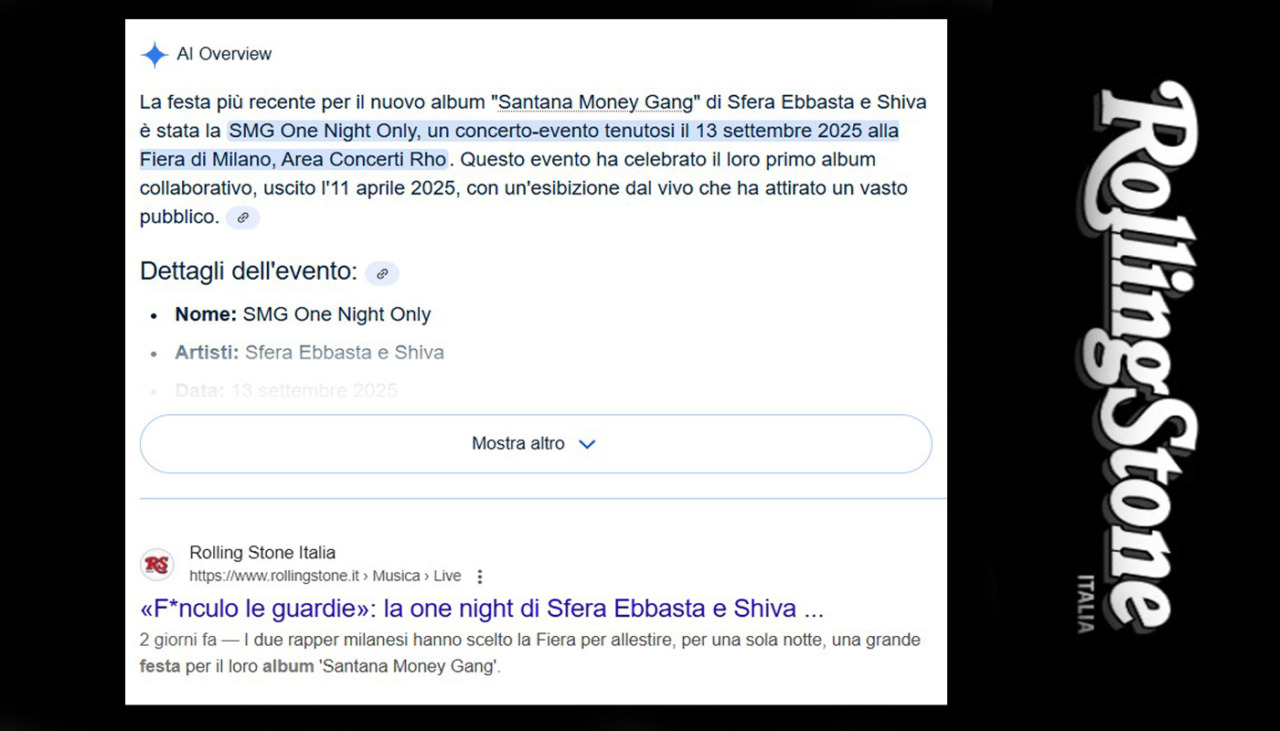
Ma se quella breve risposta basta a soddisfare la curiosità, chi clicca ancora sul sito? Secondo alcune stime, oggi il 20% delle ricerche mostra prima un’Overview AI, riducendo i clic sui risultati in prima posizione del 34,5%. Per i link in fondo alla pagina, le possibilità di essere visitati diventano quasi nulle.
L’IA si nutre dell’informazione, ma non la sostiene
La vicenda Wikipedia e quella di Google AI Overview raccontano la stessa storia: l’intelligenza artificiale sta cambiando radicalmente l’ecosistema informativo.
Da una parte, offre un vantaggio enorme agli utenti: risposte immediate, gratuite e personalizzate. Dall’altra, mette in crisi chi quelle informazioni le produce. L’IA “mangia” contenuti umani – enciclopedici o giornalistici che siano – per poi restituirli agli utenti, senza riconoscere (né remunerare) la fonte.
E non si tratta solo di perdita di visibilità. Le piattaforme generative sono spesso a pagamento, mentre i siti che forniscono i dati rimangono “a bocca asciutta”. La sfida, ora, è trovare un modello che non penalizzi le fonti originali e non riduca l’informazione a un ecosistema autoreferenziale dominato dagli algoritmi.
In gioco non c’è solo il traffico web, ma un principio fondamentale: il diritto dei cittadini a sapere da dove arriva ciò che leggono.